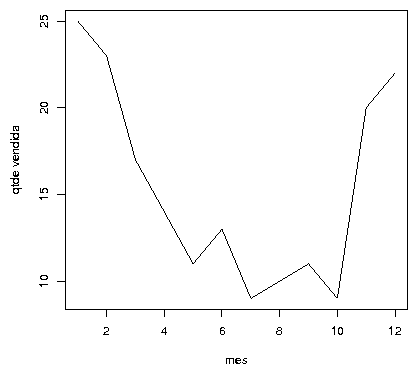
Eletrodomésticos vendidos.
> t1 <- matrix(c(1:12, 25, 23, 17, 14, 11, 13, 9, 10, 11, 9, 20,
+ 22), nrow = 2, b = T)
> t1
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
[1,] 1 2 3 4 5 6 7 8 9 10 11 12
[2,] 25 23 17 14 11 13 9 10 11 9 20 22
> dimnames(t1) <- list(c("mes", "vendas"), c("jan", "fev", "mar",
+ "abr", "mai", "jun", "jul", "ago", "set", "out", "nov", "dez"))
> t1
jan fev mar abr mai jun jul ago set out nov dez
mes 1 2 3 4 5 6 7 8 9 10 11 12
vendas 25 23 17 14 11 13 9 10 11 9 20 22